Momentan interessiere ich mich für R. Die Programmiersprache für Statistiken genießt aktuell ziemliche Popularität.
Persönlich habe ich (in der kurzen Zeit, seitdem ich es benutze und kenne) R als eine Sprache kennengelernt, die nur begrenzt für coole Sachen benutzt wird. Kann an meiner Deklaration von “cool” liegen oder das sich die coolen Sachen bisher meiner Kenntnis entzogen. Aber mal davon abgesehen dass Statistiken immer interessant sind, wird R anscheinend meistens von irgendwelchen Sales-Druiden oder Marketing-Dudes verwendet, die Daten aus der DB ihres Online-Shops kratzen lassen um festzustellen wie viele Rosa Einhörner letzten Monat verkauft worden sind.
Nunja, sagen wirs so. Ich hab überlegt für was ich R nutzen würde und etwas damit gespielt. Prinzipiell ist die vorgehensweise sehr einfach. Ich hab irgendwo ein LogFile o.ä. rumliegen (sozusagen die Rohdaten) und bringe diese mit ein bisschen Bash/Shell Zauber in ein Format welches ich R vorschmeissen kann. R unterstützt… naja so ziemlich alles, was einen halbwegs anständigen Delimiter vorweisen kann.
R arbeitet in diesem Fall mit einer Interaktiven Shell, die die Eingaben interpretiert.
Tweetstatistik meiner Timeline analysieren (via twidge)
# Letzte 200 Tweets ausgeben
$ twidge lsrecent --all > tweets
# Usernamen sortieren und Tweets zählen
$ grep '^<' tweets | awk '{print $1}' | sort | uniq -c | sort -rn
# In R Shell wechseln
$ R
# Twitter Timeline einlesen
> twittertimeline <- read.table("twitter/tweets", head=T, sep="" )
# Kuchenansicht erstellen
> pie(twittertimeline$Tweets, label=twittertimeline$User)
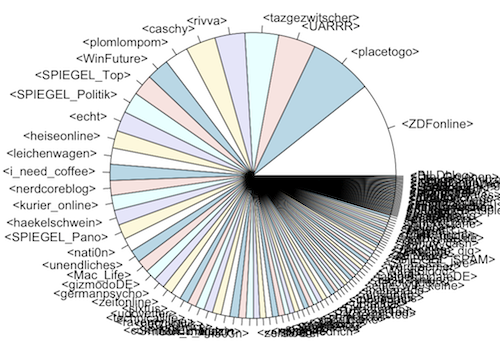
An dieser Stelle kann es passieren, dass es bei zu vielen Daten wirklich sehr unübersichtlich wird. Was genau ich da falsch mache ist mir allerdings etwas schleierhaft. An der Skalierung lässt sich sicher noch arbeiten. Aber mit einem kleineren Satz von Daten, sieht es schon besser aus.
# 20 meisten Twitterer heraussuchen
$ grep '^<' tweets | awk '{print $1}' | sort | uniq -c | sort -n | tail -20 > tweets-20
# Einlesen
> twittertimeline20 <- read.table("twitter/tweets-20", head=T, sep="")
# Balkendiagram erstellen
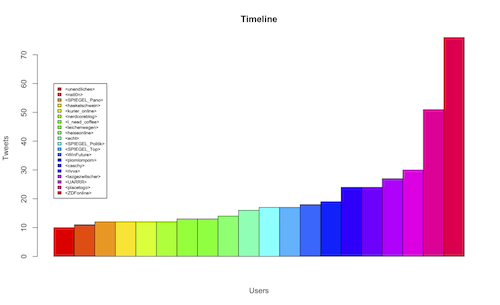
> barplot(as.matrix(twittertimeline20$Tweets), main="Timeline", ylab="Tweets", xlab="Users", beside=TRUE, col=rainbow(20))
Und damit das ganze auch was aussagt, kann man sogar eine kleine Legende anfügen.
> legend( 1, 60,twittertimeline20$User, cex=0.6, fill=rainbow(20))
History der Bash visualisieren
Wer auf Kuchen steht, kann auch eifnach mal seine Bash History einlesen.
# Command sortieren und zählen
$ history | awk '{print $4}' | sort | uniq -c | sort -rn | head > sys/history
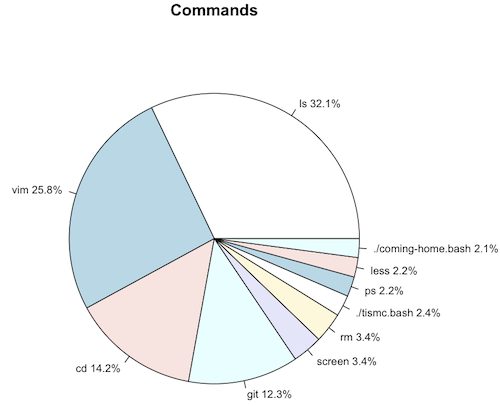
Used Command
1106 ls
889 vim
490 cd
423 git
116 screen
116 rm
81 ./tismc.bash
76 ps
75 less
72 ./coming-home.bash
# Das generierte File in R einlesen
> history <- read.table("sys/history", head=T, sep="")
# Aus dem Object history ein neues Object für Labels erstellen
# in denen die prozentualen Werte der Commands stehen
> history_labels <- paste(history$Command , " " , round(history$Used/sum(history$Used) * 100, 1) , "%", sep="")
# Object und Labels zu einem Kuchendiagramm formen
> pie(history$Used, main="Commands", label=history_labels, cex=0.8)
Mailadressen aus mail.log
Um noch ein 3. mal den Anwendungsbereich zu wechseln, kann man damit auch wunderbar das mail.log seines Mailservers unter die Lupe nehmen.
> mailaddresses <- read.table("mail/mail_addresses", head=T, sep="")
> pie(mailaddresses$Mails, main="Mail Adressen", col=rainbow(length(mailaddresses$Address) ), label=mailaddresses$Address)
Egal, mein BWL Lehrer sagte immer: Traue nie einer Statistik, die du nicht selbst gefälscht hast.
Comments (5)