Ab und zu stößt man auf etwas und fragt sich “Wie kommt das eigentlich zu
stande?”. So ging es mir die Woche mit $RANDOM. Die globale Variable der
bash liefert einen Wert zufälligen Wert zwischen 0 und 32767 zurück. Dieser
lustige kleine Integer erzeugende Kamerad ist mir jetzt nicht umbedingt neu.
2009 schrieb ich bei Codecocktail mal
einen Blogpost
darüber. Anders als damals interessierte mich aber was hinter der Value steht
und wie sie zustande kommt.
Randomness in Bash
Ich lud mir den Source der bash herunter und
laß erstmal etwas. Sollte man eigentlich öfters mal tun, weil man auch über
andere unbekannte Dinge wie z.B. $LINENO stößt. Außerdem interessante
Comments:
/* From “Random number generators: good ones are hard to find”, Park and Miller, Communications of the ACM, vol. 31, no. 10, October 1988, p. 1195. filtered through FreeBSD */
Das Paper (das nebenbei gesagt älter ist als ich) lässt schon bisschen erahnen wohin die Reise geht. Außerdem erfährt man, dass der Random Number Generator von Turbo Pascal wohl nicht so der Wahnsinn ist. Schade eigentlich.

Im Source etwas umgeschaut findet man aber schnell das was man sucht. Mit etwas Bitwise XOR Spass einen Seed auf Zeit- und PID-Basis erstellt, durch den minimalen Standard aus dem Paper gejagt und schon wars das eigentlich.
sbrand (tv.tv_sec ^ tv.tv_usec ^ getpid ());
Taugt das was?
Ich wollts dann schon noch etwas genauer wissen. Mit einem Einzeiler
S=100000000 ; time while [ $S -gt 0 ]; do echo $RANDOM >> random.txt ; ((S--)) ; done
habe ich dann (innerhalb 90 Minuten) 100 Millionen Zahlen generiert. Mein Thinkpad war von dem ganzen Gerechne (immerhin 18500 Values pro Sekunde) allerdings nicht so begeistert:
[45106.836033] intel ips: MCP limit exceeded: Avg temp 9513, limit 9000
[45106.836036] intel ips: MCP limit exceeded: Avg power 41641, limit 35000
Wahrscheinlich habe ich es etwas übertrieben. Was solls. Auf die Sample Size kommts schliesslich an!
Die 540MB große Datei hab ich dann etwas sortiert und in einen Graphen gestopft.
Die Null-Hypothese dabei: Einer der Werte ist statistisch signifikant höher als
alle anderen. Weil für Google Charts 32k Values wohl etwas zu viel ist, ein
Graph mit gnuplot
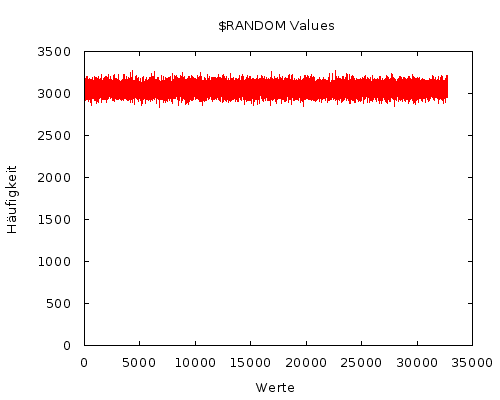
Den vielen Values gedankt sei auch die Unübersichtlichkeit des Graphen.
Deshalb noch ein kleinwenig mehr Statistikpr0n. Im Durchschnitt wird jede
der Zahlen bei 100 Mio. Durchgängen ca. 3050 mal genannt. Wesentlich
interessanter dabei ist aber die Abweichung vom Durchschnitt (siehe auch
Standard Deviation).
Bei der Bestimmung derer hilft eine kleine awk Zeile.
awk '{sum+=$1; sumsq+=$1*$1} END {print sqrt(sumsq/NR - (sum/NR)**2)}' sorted.txt
Bei meinen File wich also jeder der Werte durchschnittlich 53.6643 von der Durchschnittshäufigkeit ab. Wenn man das weiß, hat man schonmal ein ziemlich gutes Gefühl für das Auftreten der Integers.
Unterm Strich empfinde ich $RANDOM als eine mehr als zufriedenstellende
Variante eines Random Number Generators. Vielleicht war aber auch einfach
nur ein guter Tag (wörtlich!) für das zufällige generieren von Zahlen.
Comments (9)