MongoDB Cluster wollen nach der Installation wie jede andere DB getestet werden. Performance, Konsistenz bei vielen Writes, usw. Gerade bei Sharding und Indexing über mehrere Knoten verteilt möchte man das schon ausprobieren. Sind die Documents wirklich gleichmässig verteilt?

Alle Zeiten der Auswertung und Interpretation der Ergebnisse spar ich mir jetzt. Der Fokus liegt ersteinmal auf dem “wie messen”.
Write
Der einfachste Weg war das Python Modul pymongo zu benutzen, welches über
pip nachinstalliert werden kann.
import pymongo
m = pymongo.MongoClient('mongodb://user:password@localhost:27017/Database')
i = 0
doc = {'a': 1, 'b': 'foo'}
while (i < 5000000):
m.Database.testcollection.insert(doc, manipulate=False, w=1)
i = i + 1
Aufruf im Idealfall mit time python write.py, um auch wirklich die Zeit
zu messen. Die 5 Mio erstellten Documents in der Collection
testcollection, lassen sich nachher auch für Read-Tests weiterverwenden.
Read
Wie lange es dauert, alle 5 Mio Objekte aus der MongoDB auszulesen ist wahrscheinlich klar. Lange.
import pymongo
m = pymongo.MongoClient('mongodb://user:password@localhost:27017/Database')
r = m.Database.testcollection.find()
for doc in r:
print doc["_id"]
Um das komplette Datenset auszugeben: time python readall.py > allids.txt
Read Random Documents
Alle Objekte sequenziell in einem Query ausgeben ist aber ein ziemlich
exotischer Use-Case. Näher an der Realität sind kleine Queries die
zufällige Dokumente abrufen (gerade wegen des Shardings). Da sowieso schon
eine Liste aller ObjectIds existiert allids.txt hab ich dazu einfach ein
Python Skript umgebaut dass ich schon hatte.
randompopulation.py wird eine
Datei mit Input und die Anzahl der gewünschten Samples übergeben. Mithilfe
von linecache ist das auch noch sehr effizient. Die nachfolgende
modifizierte Version setzt auch gleich den MongoDB Query ab:
import random
import sys
import linecache
import pymongo
from bson.objectid import ObjectId
# configuration
population=sys.argv[1]
samplesize=int(sys.argv[2])
m = pymongo.MongoClient('mongodb://user:password@localhost:27017/Database')
# count lines of population file
def file_len(fname):
with open(fname) as f:
for i, l in enumerate(f):
pass
return i + 1
# set length to value
length=file_len(population)
# get random number with max size
x=0
while (x < samplesize):
y=(int(random.random() * length))
r=linecache.getline(population, y).rstrip('\n')
print list(m.Database.testcollection.find( { "_id": ObjectId(r) } ))
x = x + 1
Und wirft 9000 zufällige Documents aus den angelegten Datensätzen aus.
$ time python choose-random-documents.py allids.txt 9000
[{u'a': 1, u'_id': ObjectId('5399a0620ab2ccca7276853b'), u'b': u'foo'}]
[{u'a': 1, u'_id': ObjectId('5399ab530ab2ccca728a2453'), u'b': u'foo'}]
[{u'a': 1, u'_id': ObjectId('5399b0160ab2ccca72aaaf91'), u'b': u'foo'}]
[{u'a': 1, u'_id': ObjectId('5399b60f0ab2ccca72cefcde'), u'b': u'foo'}]
[{u'a': 1, u'_id': ObjectId('5399a0780ab2ccca7277341d'), u'b': u'foo'}]
[{u'a': 1, u'_id': ObjectId('5399b56c0ab2ccca72cabd93'), u'b': u'foo'}]
real 0m6.355s
user 0m3.384s
sys 0m0.512s
Distributed Read / Write
Ein Host mit Queries ist natürlich auch witzlos. Schreiben und Lesen von
mehreren Hosts! Für derartige Tasks packe ich gerne mal pssh aus.
$ pssh -h hostlist.txt -t 360 -l user -i 'python choose-random-documents.py allids.txt 25'
und selbes natürlich auch für die Write Tests
$ pssh -h hostlist.txt -t 360 -l user -i 'python write.py'
Nachdem ich in write.py noch ein paar Zeitstempel eingebaut habe, kann ich
leicht die Schreibzeiten von den Clients visualisieren.
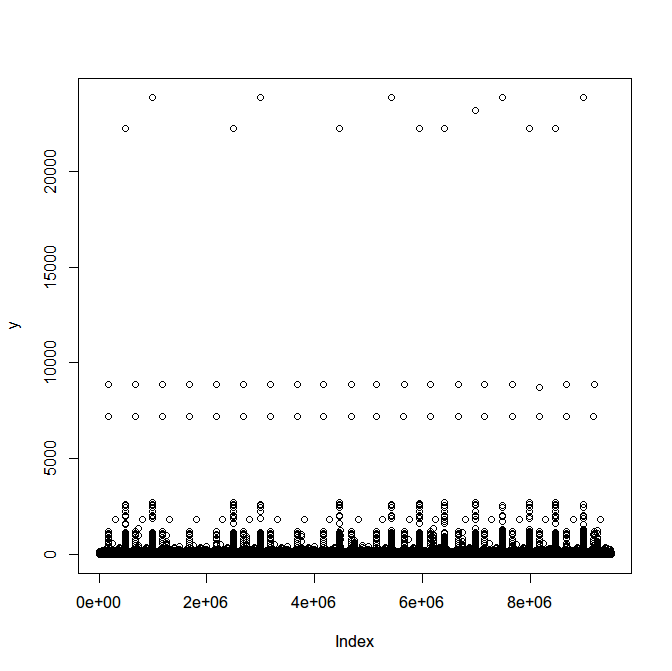
Die regelmäßigen Ausreißer beunruhigen etwas. Im Histogram visualisiert sieht das aber alles viel unproblematischer aus als im Dotchart. Es sind ja immerhin <50 Ausreißer bei 8 Mio Writes. Vertretbar.
Dataset Distribution
Nachdem alles geschrieben und gelesen ist, kann man sich auch mal anschauen wies in MongoDB aussieht. Status der Chunks anzeigen:
mongos> sh.status()
{ "_id" : "Database", "partitioned" : true, "primary" : "rs0" }
Database.testcollection
shard key: { "_id" : "hashed" }
chunks:
rs0 8
rs1 9
{ "_id" : { "$minKey" : 1 } } -->> { "_id" : NumberLong("-8278359716552185568") } on : rs0 Timestamp(2, 26)
{ "_id" : NumberLong("-8278359716552185568") } -->> { "_id" : NumberLong("-7260263158060599530") } on : rs0 Timestamp(2, 27)
{ "_id" : NumberLong("-7260263158060599530") } -->> { "_id" : NumberLong("-6016783570264293634") } on : rs0 Timestamp(2, 16)
{ "_id" : NumberLong("-6016783570264293634") } -->> { "_id" : NumberLong("-4611686018427387902") } on : rs0 Timestamp(2, 17)
{ "_id" : NumberLong("-4611686018427387902") } -->> { "_id" : NumberLong("-3654885303726982419") } on : rs0 Timestamp(2, 24)
{ "_id" : NumberLong("-3654885303726982419") } -->> { "_id" : NumberLong("-2474593789826765065") } on : rs0 Timestamp(2, 25)
{ "_id" : NumberLong("-2474593789826765065") } -->> { "_id" : NumberLong("-1237168844051948825") } on : rs0 Timestamp(2, 18)
{ "_id" : NumberLong("-1237168844051948825") } -->> { "_id" : NumberLong(0) } on : rs0 Timestamp(2, 19)
{ "_id" : NumberLong(0) } -->> { "_id" : NumberLong("960408942766083593") } on : rs1 Timestamp(2, 22)
{ "_id" : NumberLong("960408942766083593") } -->> { "_id" : NumberLong("2141950729934882470") } on : rs1 Timestamp(2, 23)
{ "_id" : NumberLong("2141950729934882470") } -->> { "_id" : NumberLong("3159510070215249954") } on : rs1 Timestamp(2, 20)
{ "_id" : NumberLong("3159510070215249954") } -->> { "_id" : NumberLong("3849612569857039248") } on : rs1 Timestamp(2, 30)
{ "_id" : NumberLong("3849612569857039248") } -->> { "_id" : NumberLong("4611686018427387902") } on : rs1 Timestamp(2, 31)
{ "_id" : NumberLong("4611686018427387902") } -->> { "_id" : NumberLong("5474895056408077106") } on : rs1 Timestamp(2, 28)
{ "_id" : NumberLong("5474895056408077106") } -->> { "_id" : NumberLong("6550645461419446020") } on : rs1 Timestamp(2, 29)
{ "_id" : NumberLong("6550645461419446020") } -->> { "_id" : NumberLong("7856429257149966918") } on : rs1 Timestamp(2, 14)
{ "_id" : NumberLong("7856429257149966918") } -->> { "_id" : { "$maxKey" : 1 } } on : rs1 Timestamp(2, 15)
Und auch wie es um die Verteilung der einzelnen Objekte steht (etwas gekürzt):
mongos> db.stats()
{
"raw" : {
"rs0/mongo01:27018,mongo02:27018" : {
"db" : "Database",
"collections" : 3,
"objects" : 3458713,
"avgObjSize" : 48.00009251996335,
"dataSize" : 166018544,
"storageSize" : 243331072,
},
"rs1/mongo03:27018,mongo04:27018" : {
"db" : "Database",
"collections" : 3,
"objects" : 3458108,
"avgObjSize" : 48.00009253614982,
"dataSize" : 165989504,
"storageSize" : 243331072,
},
"objects" : 6916821,
"avgObjSize" : 48,
"dataSize" : 332008048,
"storageSize" : 486662144,
}
Sharded Cluster Visualisierung CC-NC-BY-SA MongoDB
Comments (1)