Eingestaubt, Zukunft ungewiss. Weg von MySQL. Zeit sich endlich mal MariaDB anzusehen.

Am ehesten hat mich daran die Replikation interessiert. Einzele Bonus-Features habe ich mir dagegen nicht wirklich angesehen.
LXC Setup
Aufgrund meines lokalen LXC Setups hat sich das Testen echt einfach gestaltet. Ich habe zwei Maschinen nach diesem (empfehlenswerten) How-To aufgesetzt. Die restlichen Maschinen hab ich mit mlxc geklont.
$ C=36
$ for x in {3..7} ; do
> mlxc clone vm35-mariadb2 vm${C}-mariadb$x
> C=$(($C+1))
> done
Die Maschinen leben in einem eigenen kleinen Netz. IPs von 10.10.0.34 bis 10.10.0.40.
/home/lxc/
├── vm10-core
├── vm11-stable
├── vm12-testing
├── [...]
├── vm34-mariadb
├── vm35-mariadb2
├── vm36-mariadb3
├── vm37-mariadb4
├── vm38-mariadb5
├── vm39-mariadb6
└── vm40-mariadb7
In mariadb3 bis 7 war ich nebenbei gesagt nichtmal eingeloggt. Nur geklont, hochgefahren und selbstständig ins Cluster integriert.
Konsistenz ist kein Ort am Bodensee
Active-Active Multi-Master. Gibts für einen Sysadmin eigentlich eine schönere Kombination von 4 Wörtern? Für die Tests brauchte ich eine Database.
CREATE DATABASE test ;
CREATE TABLE test1 (id INT, data VARCHAR(100) );
Jetzt nur noch einen Testcase, mit dem ich auf zufällige Nodes
verteilt Daten schreibe. Dass $RANDOM nach der
Law of large numbers
gute Ergebnisse liefert hatten wir ja
schonmal festgestellt
Im Endeffekt wird nur ein zufälliger Host ausgewählt, INSERT/SELECT
ausgeführt und Output generiert.
$ for x in {1..1000} ; do
> H="10.10.0.$((RANDOM % 7 + 34))"
> echo -n "Write ID $x on $H: "
> mysql -BN -u root -ppassword -h $H -e \
> "INSERT INTO test.test1 (id,data) VALUES ($x , 'foo'); \
> SELECT id FROM test.test1 ORDER BY id DESC LIMIT 1;"
> done
[...]
Write ID 517 on 10.10.0.40: 517
Write ID 518 on 10.10.0.35: 518
Write ID 519 on 10.10.0.38: 519
Write ID 520 on 10.10.0.37: 520
Write ID 521 on 10.10.0.35: 521
[...]
Ich war überrascht, wie flüssig das geht ohne jegliches “verschlucken”. Anfangs
hatte ich sleep Commands eingebaut. Ich war misstrauisch, dass es
zu Konflikten kommen könnte. Immerhin beschiesse ich 7 verschiedene Hosts
im Millisekundentakt mit INSERT Statements.
Auch deswegen hab ich es mir nicht nehmen lassen das Ergebnis erstmal zu verifizieren.
$ for x in {34..40} ; do
> echo -n "No. of Entries on 10.10.0.$x: "
> mysql -BNe 'SELECT COUNT(id) from test.test1;' -h 10.10.0.$x -u root -ppassword
> done
No. of Entries on 10.10.0.34: 1000
No. of Entries on 10.10.0.35: 1000
No. of Entries on 10.10.0.36: 1000
No. of Entries on 10.10.0.37: 1000
No. of Entries on 10.10.0.38: 1000
No. of Entries on 10.10.0.39: 1000
No. of Entries on 10.10.0.40: 1000
Alles komplett. Spannend.
Performance
Zum Ende hin hab ich noch ein bisschen Zeit gemessen. Zugegeben ist das null representativ, weil weder richtiges Netzwerk dazwischen ist, noch verschiedene Platten. Um ein bisschen Gefühl für die Angelegenheit zu bekommen wars aber hilfreich.
for x in {1..10000} ; do
H="10.10.0.$((RANDOM % 7 + 34))"
(time mysql -BN -u root -ppassword -h $H -e "INSERT INTO test.test1 (id,data) VALUES ($x , 'foo');" ) 2>&1 | grep real
done > latency.txt
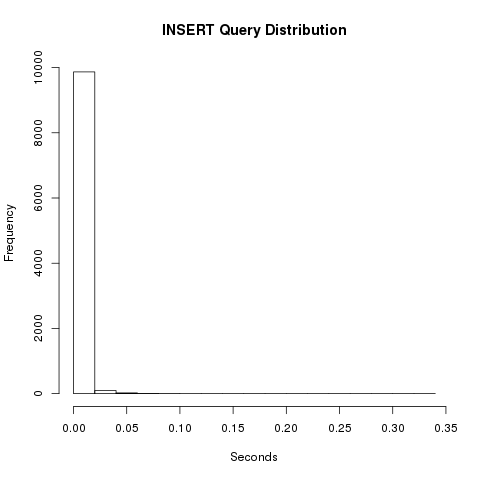
Die Zahlen hab ich dann noch in R geschmissen.
seconds
Min. :0.00600
1st Qu.:0.01100
Median :0.01300
Mean :0.01291
3rd Qu.:0.01400
Max. :0.32300
Std Dev:0.00508
Die Zahlen wirken sehr stabil. Wenig schwankend, alle im erträglichen Bereich. Verteilung sieht auch in Ordnung aus.
Jetzt will ich nur noch, dass Kunden das auch haben wollen.
Comments (7)