Ich durfte wie bereits erwähnt auf den Chemnitzer LinuxTagen einem Vortrag zur Geschichte von Versionskontrollsystemen und dem Revival von SCCS lauschen. Diesen fand ich unter anderem (besonders beim Historischen) informativ und unterhaltsam.

Nicht übereinstimmen kann ich aber in den angebrachten “Vergleichen” von SCCS zu (unter anderem) git. Die Vortragsfolien können hier angesehen werden.
Die Repository Initalisierung
Initalisierung aller OpenSolaris Source Files:
SCCS: 8 Sekunden git: 100 Sekunden
Aus dem Hörsaal kam die berechtigte Frage:
Wie oft mache ich das?
Ich denke das spricht schonmal für sich, aber das eigentliche Feature hierbei ist, dass git von allen Files im Repo einen Binärblob in .git/ ablegt. Während SCCS nur Diffs vom letzten zum neuen Commit speichert.
Das hab ich mal nachgebaut, kommt schon hin:
$ time git add .
real 0m38.405s
user 0m17.121s
sys 0m2.620s
$ time git commit -a -m "init"
real 0m26.078s
user 0m6.132s
sys 0m1.660s
Nachvollziehbar, dass git länger dafür braucht alle Files zu kopieren als SCCS mit “Ah, hier ist noch ein File, schreib ich den Namen des Files mal in meine Liste”.
Das Datenvolumen
Die angesprochenen Werte auf Seite 36 der Präsentation beziehen sich auf simple Timestamps. Jörg Schilling hat hier 2 Mio. Timestamps erstellt und mit git und sccs jeden davon mit jeweils einem Commit abgeschlossen.
Platzbedarf mit SCCS ca. 300 MB (komprimiert 160 MB) Platzbedarf mit GIT geschätzt: ca. 15 TB
Ich war so frei das einfach mal (aus zeitlichen Gründen mit 1 Mio. Files) nachzustellen:
#!/bin/bash
touch test
git add test
C=0
time while [ $C -le 1004225 ]; do
date "+%Y%m%d %H%M%s%N" > test
git commit -a -m "$C"
((C++))
done
Größe nach dem Command:
$ du -sh /tmp/1miocommits/
12G .
Ich bin mir nicht sicher was Jörg hier genau getan hat. Meine Testwerte unterscheiden sich jedenfalls erheblich von dem, was im Vortrag vorkommt.
Unter anderem wurde erwähnt, dass die Größe des Git Repositories hochgerechnet wurde. Nun das ist natürlich insofern doof, wie man weiss das git Deduplication betreibt. Teile aus den Blobs werden einmalig aufgehoben, wenn sie idientisch sind. So lässt sich viel Platz sparen und das Konstrukt des “Hochrechnens” bricht zusammen. Selbst wenn ich das jetzt nur verdopple kommen dabei 24 GB statt 15 TB raus.
Die Zeit
Ein weiterer Punkt der meines Erachtens beim Vergleich von git zu SCCS außer acht gelassen wurde. Die Zeit.
Was mich sehr interessiert sind die Wiederherstellzeiten. Klar git hat einen spezifischen Commit welcher auf ein Objekt im Hash Store zeigt. Dieser wird ausgelesen und fertig ist die Wiederherstellung.
(Bild von progit.org - Creative Commons Attribution Non Commercial Share Alike 3.0 license)
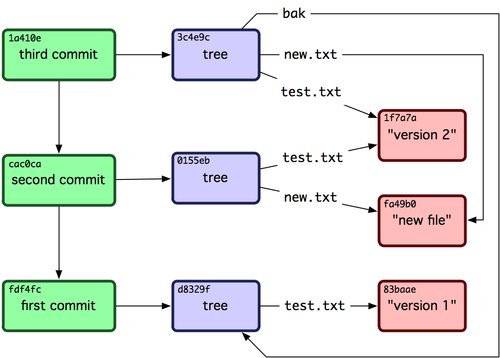
Aber bei SCCS? Angenommen ich möchte vom 1.000.000 Commit zum 1. zurück. Alle Diffs werden dazu auf das aktuelle File angewandt und zurückgerechnet bis das File wieder am Ursprungszustand angekommen ist. Ob das Spass macht?
Die Konsistenz
Selbes Szenario hier. Ich weiss nicht was passiert wenn das Diff File von SCCS unterwegs mal kaputt geht. Aus welchen Gründen auch immer. HDD Block kaputt oder versehentlich editiert. Faktisch sollte das File dann nicht mehr herstellbar sein.
Bei git bleibt weiterhin der mit zlib komprimierte Binary Blob bestehen und alles ist gut weil wie oben der Commit auf einen binär Blob referenziert. Selbst wenn dazwischen mal ein Block eines Blobs kaputt sein sollte (oder was auch immer).
Ende
Ich möchte zum Schluss nochmal unterstreichen, dass ich in keinster Weise den Vortrag oder die Weiterentwicklung von Jörg Schilling an SCCS kritisieren will. Im Gegenteil. SCCS ist für bestimmte Einsatzzwecke bestimmt nett, eben weil es “anders” ist als git. Aber, dass SCCS in allen Punkte besser als git möchte ich nicht unterschreiben.
Comments (2)